在深度学习领域,飞桨开源框架一直以其强大的功能和广泛的应用备受瞩目。近日,其旗下的文字识别开发套件PaddleOCR迎来了v2.8.0的里程碑式更新,这一版本不仅引入了前沿的OCR技术,还对项目结构进行了深度优化,为用户带来了更为稳定、兼容和高效的体验。
注:文中图片来自官方网站截图,仅供参考
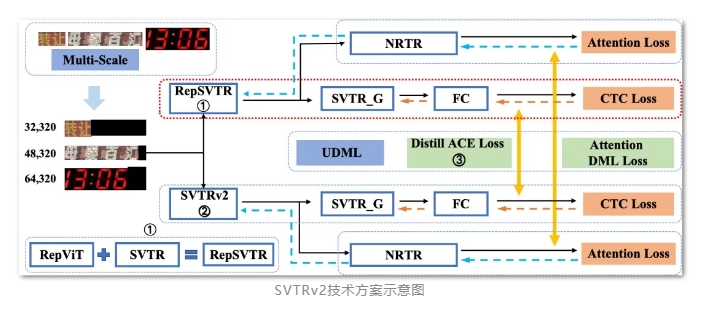
PaddleOCR v2.8.0的最大亮点在于其引入了众多前沿的OCR技术。其中,PaddleOCR算法模型挑战赛的冠军方案——场景文本识别算法SVTRv2和表格识别算法SLANet-LCNetV2的加入,无疑为OCR领域树立了新的标杆。这两种算法在识别准确率和效率方面都有着出色的表现,能够更好地应对复杂多变的实际应用场景。
除了技术上的革新,PaddleOCR v2.8.0还对项目结构进行了大刀阔斧的改革。非核心模块被迁移至新仓库,使得整个项目更加聚焦于OCR核心技术的研究与发展。这种优化不仅提高了项目的整体运行效率,也为后续的版本迭代奠定了坚实的基础。
在用户体验方面,PaddleOCR v2.8.0同样不遗余力。针对用户反馈的更新Backbone后模型无法运行、numpy版本依赖冲突以及Mac系统运行卡顿等历史疑难问题,新版本都进行了针对性的修复和优化。此外,新版本还修复了版面分析中OCR结果丢失的问题,并引入了pyproject.toml以符合PEP518规范,进一步提升了软件的稳定性和兼容性。
值得一提的是,PaddleOCR v2.8.0的每一次进步都离不开开源社区的支持和贡献。PMC成员和贡献者们的不懈努力,为这款软件的成功迭代提供了强有力的保障。未来,PaddleOCR将继续秉承开源精神,与全球开发者共同推动OCR技术的进步与发展。
据悉,PaddleOCR正在积极建设文档教程专属站点,为用户提供更加便捷、高效的学习体验。届时,用户可以通过关键词检索功能快速找到所需教程,并在优雅舒适的界面中轻松掌握OCR技术的精髓。
想要了解更多关于PaddleOCR v2.8.0的详细信息吗?点击链接访问项目官网:https://github.com/PaddlePaddle/PaddleOCR ,一起开启OCR技术的新篇章!






















 渝公网安备50011802010872
渝公网安备50011802010872